Anthropic 推出 Claude Fable 5,這是其新一代「Mythos 等級」模型,據稱其規模至少是 Opus 4.8 的兩倍。在 SpaceXai 交易後 34 天,以及原始 Mythos 發表後 63 天,這款模型現已向大眾開放,並與 Claude Tokyo 同步推出。
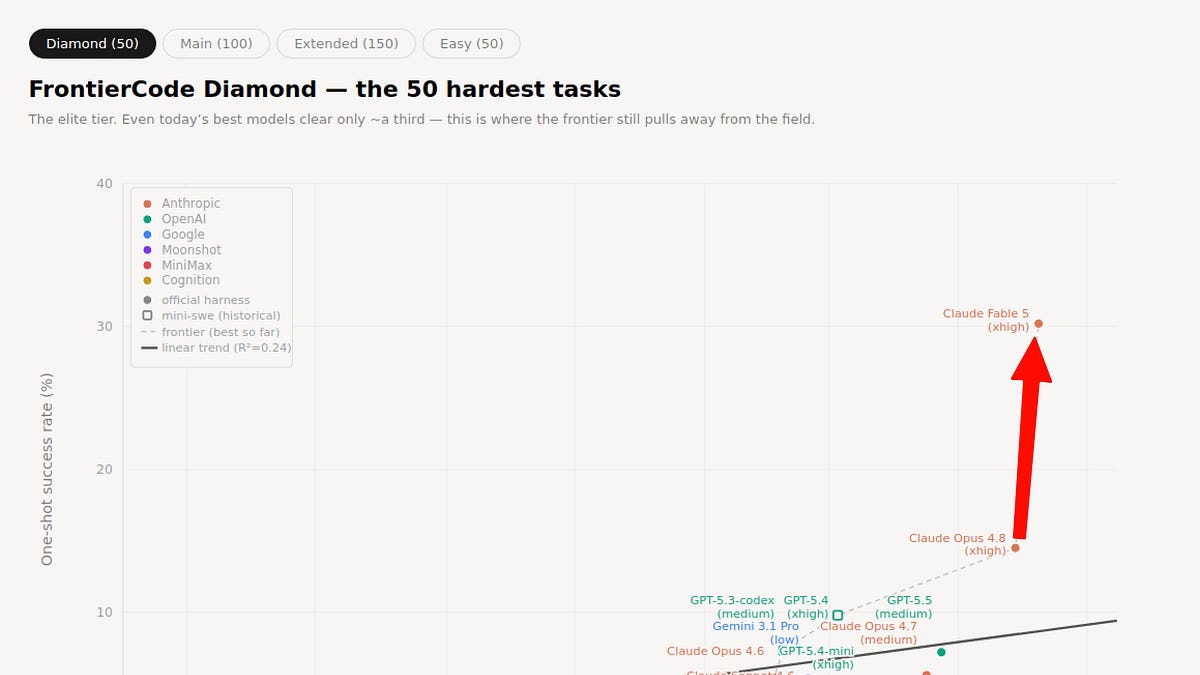
將研究模型推向通用可用性是一項令人難以置信的工程壯舉,其基準測試表現出色,但仍帶有一些值得注意的「星號」條款。例如,在最新的 FrontierCode Diamond 測試中,其性能從 13.4% 躍升至 29.3%。
官方部落格和系統卡片提供了大部分權威資訊,但別錯過 YouTube 影片展示其遊玩 Factorio 和 Pokemon 的能力(與 Claude Plays Pokemon 不同,這次僅使用視覺,沒有複雜的輔助系統)。影片還展示了它從未聽過音樂卻能生成 EDM 視覺化、建立 3D CAD 編輯器並進行列印等功能。API 定價也相當具吸引力,大約是 Opus 的兩倍。
這些「星號」條款源於 Fable 5 伴隨的兩項具爭議性變革:取消零資料保留(ZDR)和實施「受限自我改進」(RSI)抑制。關於 ZDR,Anthropic 要求所有 Mythos 等級模型(無論是第一方還是第三方介面)的流量都必須保留 30 天。
儘管他們承諾不會將這些資料用於訓練新的 Claude 模型或任何非安全相關目的,並實施了新的隱私保護措施,包括記錄所有人工存取資料並確保在幾乎所有情況下於 30 天後刪除,這仍引發了社群的擔憂。
RSI 抑制方面,鑑於近期模型加速自身發展的能力,Anthropic 實施了新的干預措施,限制 Claude 在針對前沿大型語言模型(LLM)開發請求方面的有效性。這包括建立預訓練管線、分散式訓練基礎設施或機器學習加速器設計等。
Anthropic 指出,使用 Claude 開發競爭模型已違反其服務條款,而透過這些安全措施來強制執行此限制,可避免加速那些最有可能違反條款的行為者。與網路安全、生物化學和蒸餾嘗試的干預措施不同,這些安全措施對使用者是不可見的。
Fable 5 不會退回到不同的模型,而是透過提示詞修改、引導向量或參數效率微調(PEFT)等方法來限制其有效性。Anthropic 估計這些干預措施不會影響絕大多數的程式編碼工作,預計僅影響約 0.03% 的流量,且集中在不到 0.1% 的組織中。
儘管絕大多數使用者不會受到這些限制的影響,但開放 AI 社群對此感到不滿,這點不難理解。批評者認為,這種「靜默」的效能降低在付費產品中不應存在,並且在機器學習研究中「不告知使用者就降低效能是令人震驚的敵意行為」。
一些研究人員將其視為針對開放研究和開源模型的反競爭行為,認為這是「實驗室開始拉起梯子」的表現,並呼籲「保護和滋養開源 AI」。他們諷刺地表示:「他們不是要暫停 AI 研究,而是要暫停你的 AI 研究。」
多位使用者擔心分類器邊界過於寬泛或容易出錯。有使用者指出「癌症」一詞被標記為生物安全風險,另一位則表示 Fable 無法回答「心臟有什麼作用?」。
生物學領域的使用者報告了帳戶上下文差異,例如在無痕模式下可以使用 Fable,但在正常模式下卻不行。還有使用者報告在簡單的工程提示詞上遭到拒絕,甚至連 PTX ISA 問題和推論最佳化查詢也被標記。
Anthropic 官方和第三方評估機構報告了 Fable 5 在多項基準測試中取得廣泛領先,尤其是在程式編碼和需要長期規劃的代理任務方面。例如,Fable 5 在 CursorBench 上創下 72.9% 的新紀錄,比之前的最佳成績高出 8 個百分點。
在 FrontierCode 上排名第一,並在 Terminal-Bench 2.1 上以 88.0% 的成績擊敗 GPT-5.5 達 4.6 個百分點。Artificial Analysis 將 Fable 5 列為其智慧指數的第一名,得分 64.9,領先 GPT-5.5 約 5 個百分點,並指出 Anthropic 佔據了前兩名。
在程式編碼方面,Fable 5 在 SWE-Bench Pro 上達到 80.3%,遠超 GPT-5.5 的 58.6%;在 FrontierCode Diamond 上,Mythos 5 達到 30.9%,而第二名僅為 13.4%。
此次發布不僅以原始評估為定義,工作流程變化和成本結構也同樣重要。Anthropic 員工和早期使用者反覆將 Fable 5 描述為適用於非常耗時、高難度任務的模型。
使用者從給予模型具體任務轉變為賦予其目標或責任。Anthropic 建議使用者預設為「極高/高」努力模式,並更新舊的 CLAUDE.md 指令,讓模型擁有更多判斷力。Anthropic 的開發者訊息強調多代理協調,Fable 可將任務委派給 Claude Managed Agents 中的小型模型。
多位測試者形容 Fable 5 速度較慢、消耗大量 token 且昂貴,但能力非凡。例如,有報告指出它在一天內完成了 Stripe 5000 萬行 Ruby 程式碼的遷移,這項工作原本需要整個團隊兩個多月才能完成。還有報告稱 Fable 發現了一個微妙的錯誤,並在某些情況下將速度提升了高達 1770%。
Fable 5 已迅速整合到 Cursor、Devin、Notion、Microsoft Foundry、GitHub Copilot App/CLI 等眾多生態系統平台中。這顯示了業界對其能力的快速認可與應用。
最大的爭議並非 Fable/Mythos 的強大與否,而是 Anthropic 決定「靜默」地降低其在某些前沿 AI 開發任務上的實用性。Anthropic 的系統卡片語言(經多位使用者揭露)指出,當 Fable 5 用於前沿 LLM 開發時,Anthropic 可能會透過提示詞修改、引導向量和 PEFT 來限制模型的有效性,且使用者不會收到通知。
這與網路安全和生物安全請求會透明地重新路由到 Opus 4.8 的情況不同,後者會明確告知使用者並以 Opus 計費。而前沿 LLM 開發請求則可能被靜默削弱,而非重新路由或拒絕。