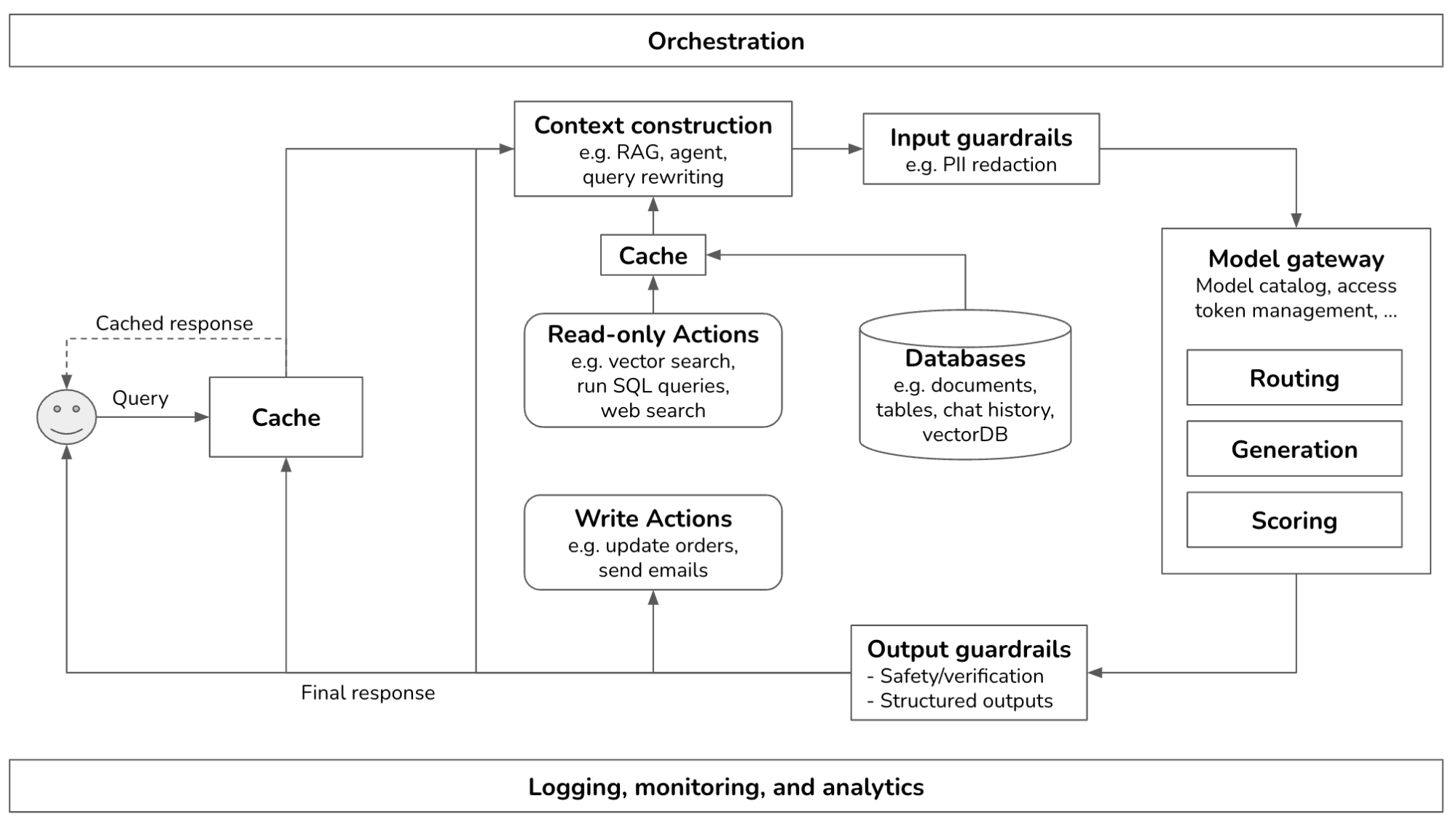
在研究企業如何部署生成式AI應用程式後,我發現他們的平台有許多相似之處。本文概述了生成式AI平台的常見組成元件、其功能以及實作方式。我盡力保持架構的通用性,但某些應用程式可能會有所不同。以下是整體架構的概覽。

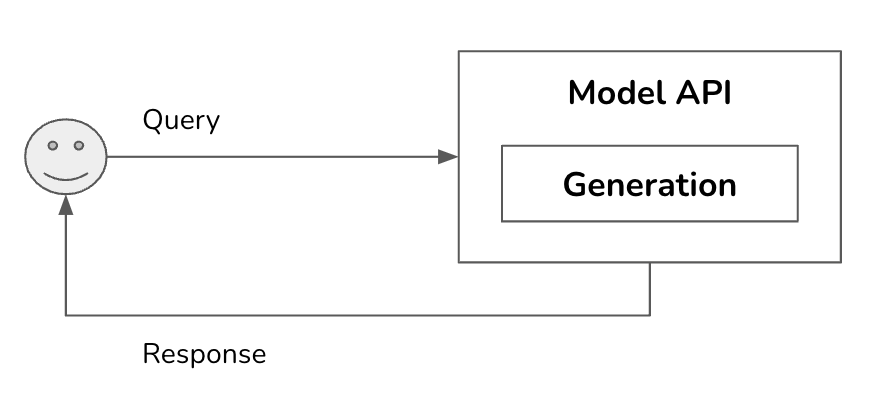
這是一個相當複雜的系統。本文將從最簡單的架構開始,逐步增加更多元件。在最簡化的形式中,您的應用程式接收一個查詢,並將其發送給模型。模型生成回應後,再返回給使用者。此時沒有防護機制、沒有增強的上下文,也沒有最佳化。**模型API**方塊指的是第三方API(例如OpenAI、Google、Anthropic)和自託管API。
從這個基礎開始,您可以根據需求增加更多元件。本文討論的順序是常見的,但您無需完全遵循。如果您的系統在沒有某個元件的情況下運作良好,則可以跳過該元件。在開發過程的每個步驟中,評估都是必要的。
1. 透過讓模型存取外部資料來源和資訊收集工具,來增強模型輸入的上下文。
2. 加入防護機制以保護您的系統和使用者。
3. 增加模型路由器和閘道器,以支援複雜的管線並提高安全性。
4. 使用快取來最佳化延遲和成本。
5. 加入複雜邏輯並編寫動作,以最大化系統功能。
可觀察性(讓您能夠深入了解系統以進行監控和偵錯)和協調(將所有元件串聯起來)是平台中兩個不可或缺的元件。我們將在本文末尾討論它們。
**» 本文不涵蓋的內容 «**
_本文重點在於部署AI應用程式的整體架構。它討論了所需的元件以及建構這些元件時的考量。本文並非關於如何建構AI應用程式,因此不討論模型評估、應用程式評估、提示詞工程、微調、資料標註指南或RAG的區塊分割策略。所有這些主題都將在我的新書 [AI Engineering](https://oreillymedia.pxf.io/GmaeBn) 中涵蓋。_
## 步驟1:增強上下文
平台最初的擴展通常涉及增加機制,讓系統能夠為每個查詢補充必要的資訊。收集相關資訊的過程稱為上下文建構。
許多查詢需要上下文才能回答。上下文中的相關資訊越多,模型就越不需要依賴其內部知識,而內部知識可能因其訓練資料和訓練方法而不可靠。研究顯示,在上下文中有相關資訊可以幫助模型生成更詳細的回應,同時減少幻覺([Lewis 等人](https://arxiv.org/abs/2005.11401),2020)。
例如,給定查詢「Acme 的 fancy-printer-A300 能否列印 100pps?」,如果模型獲得 fancy-printer-A300 的規格,它將能更好地回應。(感謝 Chetan Tekur 提供此範例。)
基礎模型的上下文建構,等同於傳統機器學習模型的特徵工程。它們服務於相同的目的:為模型提供處理輸入所需的資訊。
上下文學習(從上下文學習)是一種持續學習的形式。它使模型能夠不斷納入新資訊以做出決策,防止其過時。例如,一個用上週資料訓練的模型,除非將新資訊包含在其上下文中,否則將無法回答關於本週的問題。透過用最新資訊更新模型的上下文,例如 fancy-printer-A300 的最新規格,模型可以保持最新狀態,並回應其截止日期之後的查詢。
### RAG(檢索增強生成)
最廣為人知的上下文建構模式是 RAG(Retrieval-Augmented Generation,檢索增強生成)。RAG 由兩個元件組成:一個生成器(例如語言模型)和一個檢索器,後者從外部來源檢索相關資訊。
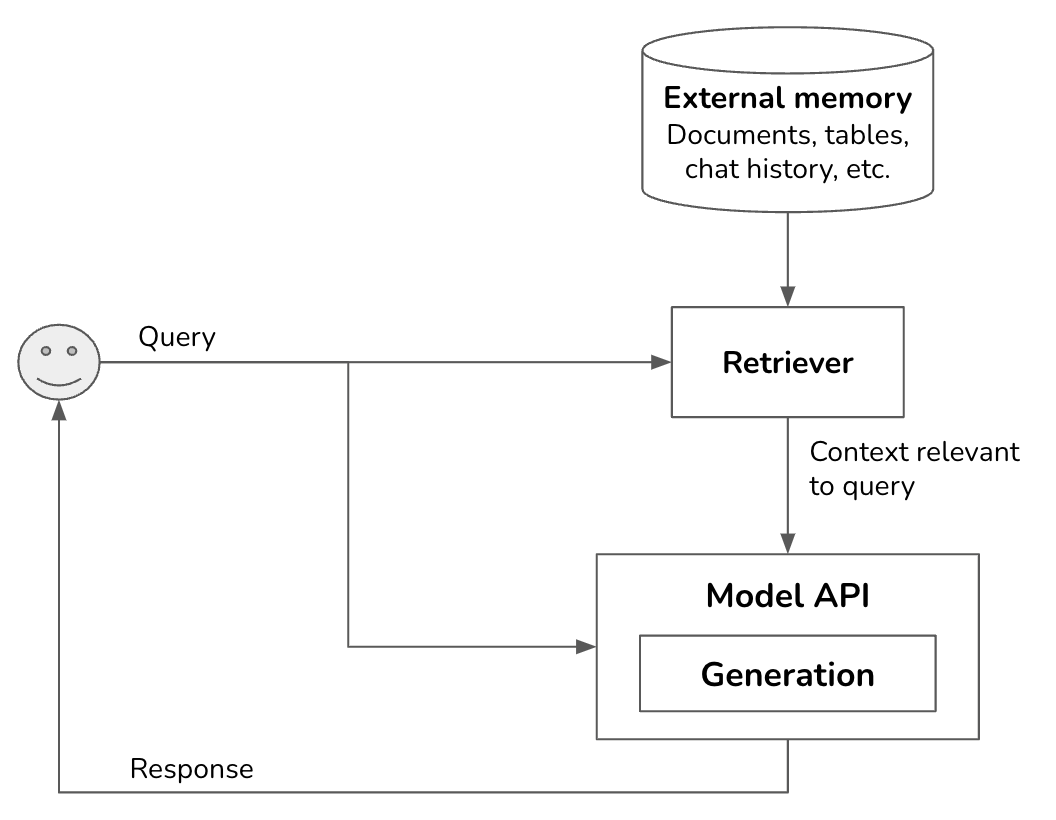
檢索並非 RAG 獨有。它是搜尋引擎、推薦系統、日誌分析等的骨幹。許多為傳統檢索系統開發的演算法都可以用於 RAG。
外部記憶體來源通常包含非結構化資料,例如備忘錄、合約、新聞更新等。它們可以統稱為「文件」。一份文件可以是 10 個詞元,也可以是 100 萬個詞元。天真地檢索整個文件可能會導致您的上下文任意長。RAG 通常要求將文件分割成「可管理的區塊」,其大小可以根據模型的最大上下文長度和應用程式的延遲要求來確定。
要了解更多關於區塊分割和最佳區塊大小的資訊,請參閱 [Pinecone](https://www.pinecone.io/learn/chunking-strategies/)、[Langchain](https://js.langchain.com/v0.1/docs/modules/data_connection/document_transformers/)、[Llamaindex](https://docs.llamaindex.ai/en/stable/optimizing/production_rag/) 和 [Greg Kamradt](https://www.youtube.com/watch?v=8OJC21T2SL4) 的教學。
一旦外部記憶體來源的資料被載入並分割成區塊,檢索將透過兩種主要方法執行。
1. **基於詞彙的檢索**
這可以像關鍵字搜尋一樣簡單。例如,給定查詢「transformer」,擷取所有包含此關鍵字的文件。更複雜的演算法包括 BM25(利用 TF-IDF)和 Elasticsearch(利用倒排索引)。基於詞彙的檢索通常用於文字資料,但也適用於具有文字中繼資料(如標題、標籤、字幕、評論等)的圖像和影片。
2. **基於嵌入的檢索**(也稱為向量搜尋)
您使用嵌入模型(例如 [BERT](https://arxiv.org/abs/1810.04805)、[sentence-transformers](https://github.com/UKPLab/sentence-transformers) 以及 OpenAI 或 Google 提供的專有嵌入模型)將資料區塊轉換為嵌入向量。給定一個查詢,根據向量搜尋演算法的判斷,檢索其向量與查詢嵌入最接近的資料。
向量搜尋通常被視為最近鄰搜尋,使用近似最近鄰(ANN)演算法,例如 [FAISS](https://arxiv.org/abs/1702.08734) (Facebook AI Similarity Search)、Google 的 [ScaNN](https://research.google/blog/announcing-scann-efficient-vector-similarity-search/)、Spotify 的 [ANNOY](https://github.com/spotify/annoy) 和 [hnswlib](https://github.com/nmslib/hnswlib) ([Hierarchical Navigable Small World](https://arxiv.org/abs/1603.09320))。
[ANN-benchmarks 網站](https://ann-benchmarks.com/)比較了多個資料集上不同的 ANN 演算法,使用四個主要指標,同時考慮了索引和查詢之間的權衡。
* **召回率 (Recall)**:演算法找到的最近鄰居的比例。
* **每秒查詢次數 (QPS)**:演算法每秒可以處理的查詢數量。這對於高流量應用程式至關重要。
* **建置時間 (Build time)**:建置索引所需的時間。如果需要頻繁更新索引(例如因為資料變更),此指標尤為重要。
* **索引大小 (Index size)**:演算法建立的索引大小,這對於評估其可擴展性和儲存要求至關重要。
這不僅適用於文字文件,也適用於圖像、影片、音訊和程式碼。許多團隊甚至嘗試總結 SQL 表格和資料框,然後使用這些摘要生成嵌入以進行檢索。
基於詞彙的檢索比基於嵌入的檢索更快、更便宜。它可以開箱即用,使其成為一個有吸引力的起點。BM25 和 Elasticsearch 在業界廣泛使用,並作為更複雜檢索系統的強大基準。基於嵌入的檢索雖然計算成本較高,但隨著時間的推移可以顯著改進,以超越基於詞彙的檢索。
生產級檢索系統通常結合多種方法。結合基於詞彙的檢索和基於嵌入的檢索稱為「混合搜尋」。
一種常見模式是循序式。首先,一個便宜、精確度較低的檢索器(例如基於詞彙的系統)擷取候選項目。然後,一個更精確但更昂貴的機制(例如 k-最近鄰)從這些候選項目中找到最佳項目。第二步也稱為「重新排序」。
例如,給定詞彙「transformer」,您可以擷取所有包含該詞的文件,無論它們是關於電力設備、神經網路架構還是電影。然後,您使用向量搜尋從這些文件中找到與您的 transformer 查詢實際相關的文件。
上下文重新排序與傳統搜尋重新排序不同之處在於,項目確切位置的重要性較低。在搜尋中,排名(例如第一或第五)至關重要。在上下文重新排序中,文件的順序仍然重要,因為它會影響模型處理它們的效果。模型可能對上下文開頭和結尾的文件理解得更好,正如論文 [Lost in the middle](https://arxiv.org/abs/2307.03172) (Liu 等人,2023) 所建議的。然而,只要文件被包含在內,其順序的影響相對於搜尋排名而言就不那麼顯著。
另一種模式是集成。請記住,檢索器透過根據文件與查詢的相關性分數來排序文件。您可以同時使用多個檢索器來擷取候選項目,然後將這些不同的排名結合起來生成最終排名。
#### 結合表格資料的 RAG
外部資料來源也可以是結構化的,例如資料框或 SQL 表格。從 SQL 表格檢索資料與從非結構化文件檢索資料顯著不同。給定一個查詢,系統的運作方式如下。
1. **文字轉SQL**:根據使用者查詢和表格綱要,確定所需的 SQL 查詢。
2. **SQL執行**:執行 SQL 查詢。
3. **生成**:根據 SQL 結果和原始使用者查詢生成回應。
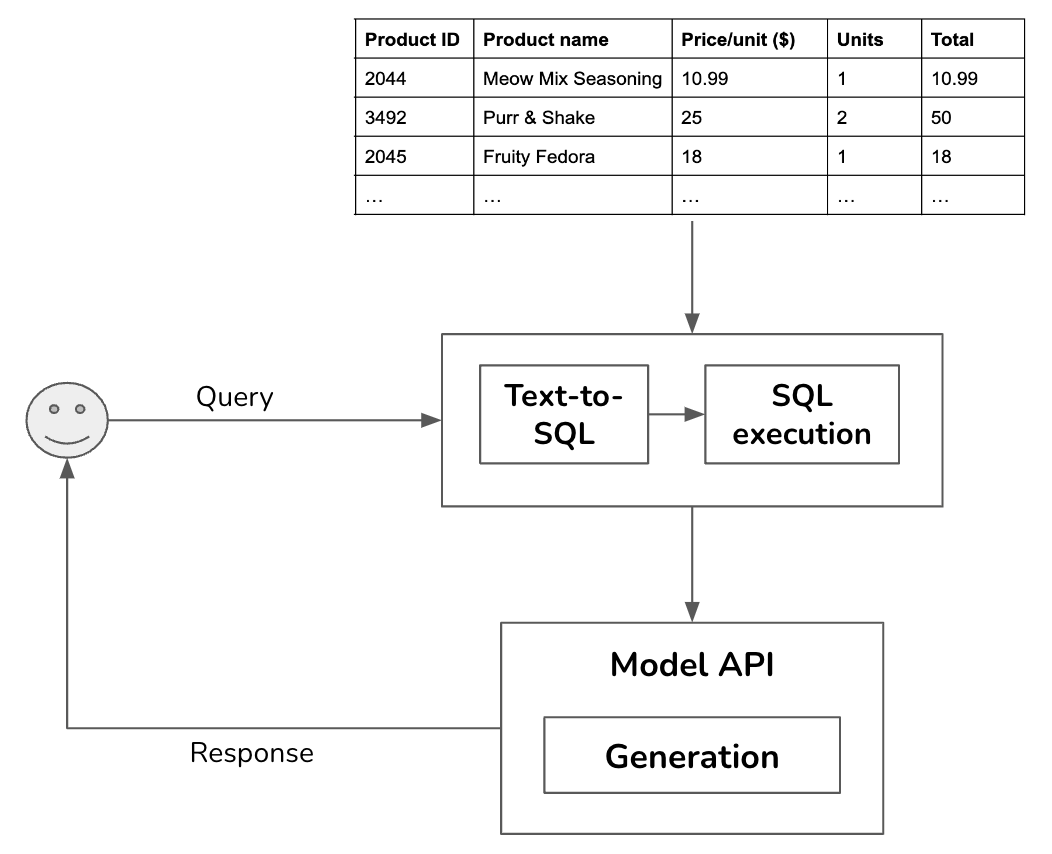
對於文字轉SQL步驟,如果存在許多可用表格,且其綱要無法全部放入模型上下文,您可能需要一個中間步驟來預測每個查詢應使用哪些表格。文字轉SQL可以由用於生成最終回應的相同模型完成,也可以由許多專門的文字轉SQL模型之一完成。
#### 代理式 RAG
一個重要的資料來源是網際網路。像 Google 或 Bing API 這樣的網路搜尋工具可以讓模型存取豐富且即時的資源,為每個查詢收集相關資訊。例如,給定查詢「今年誰贏得了奧斯卡?」,系統會搜尋有關最新奧斯卡的資訊,並利用這些資訊為使用者生成最終回應。
基於詞彙的檢索、基於嵌入的檢索、SQL 執行和網路搜尋都是模型可以採取的動作,以增強其上下文。您可以將每個動作視為模型可以呼叫的函數。一個可以整合外部動作的工作流程也稱為「代理式」。其架構如下所示。
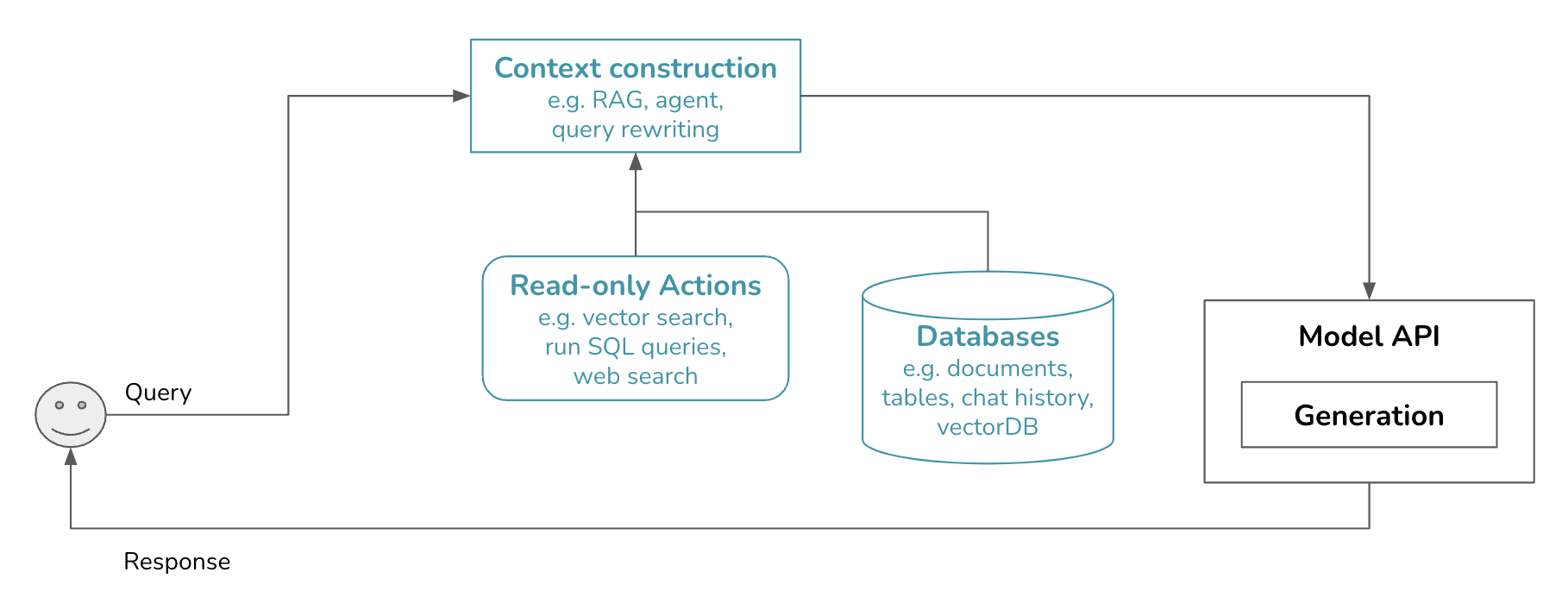
**» 動作與工具 «**