觀點
IBM Granite 4.1 模型圖像生成實測:鵜鶘騎自行車
摘要
IBM 近期發布了 Granite 4.1 系列大型語言模型。Simon Willison 針對其中 3B 模型的 GGUF 量化版本進行了一項實驗,測試其生成「騎自行車的鵜鶘」SVG 圖像的能力。然而,實驗結果不如預期,不同大小的模型在圖像品質上並無顯著差異,且整體表現不佳。
IBM 於數日前發布了 Granite 4.1 系列大型語言模型(LLM)。這些模型採用 Apache 2.0 授權,並提供 3B、8B 和 30B 等不同規模的版本。
Granite 團隊成員 Yousaf Shah 所撰寫的《Granite 4.1 LLMs: How They’re Built》一文,詳細描述了這些模型的訓練過程。
Unsloth 發布了 unsloth/granite-4.1-3b-GGUF 系列,其中包含 3B 模型的 GGUF 編碼量化變體,共有 21 種不同的模型檔案,大小從 1.2GB 到 6.34GB 不等。
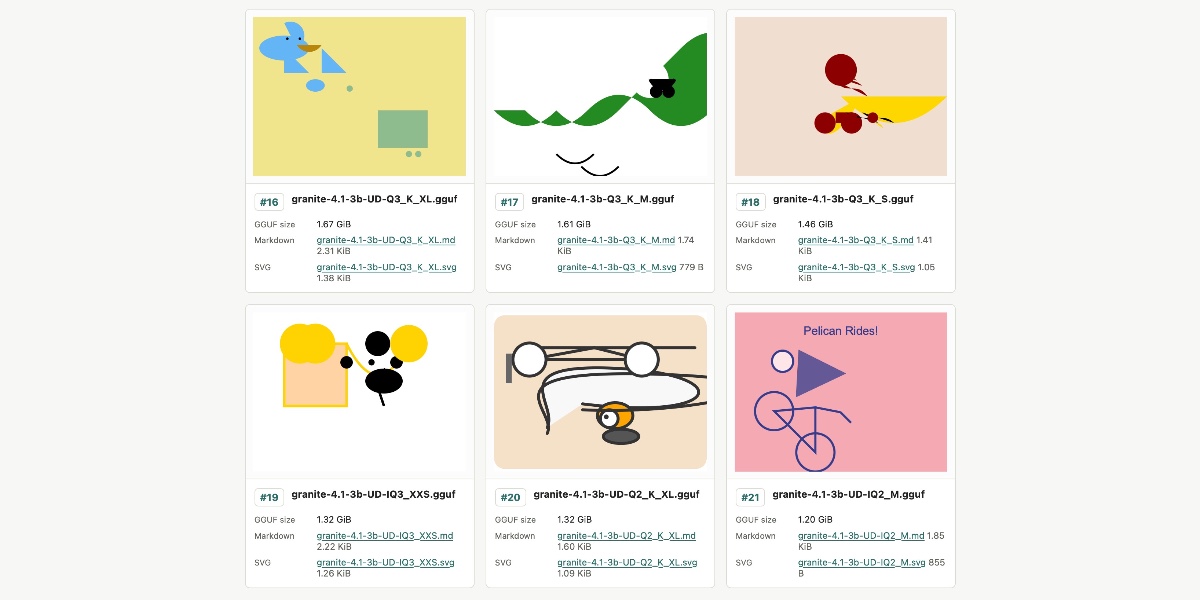
這 21 個 Unsloth 檔案總計達 51.3GB,這啟發我終於嘗試了一項我渴望已久的實驗:針對相同模型的不同大小量化變體,提示「生成一張騎自行車的鵜鶘 SVG 圖像」,以觀察其生成結果。
老實說,結果不如我預期地有趣。圖像品質與模型大小之間沒有可辨識的模式——它們的表現都相當糟糕!
圖片 1:六張來自 1.67GB 到 1.2GB 不同大小模型的 SVG 圖像。它們幾乎都是抽象的形狀集合——奇怪的是,最小的模型生成了最好的自行車版本,而最大的模型則生成了略微像鵜鶘的東西。
未來我可能會再次嘗試這項實驗,但會選用更擅長繪製鵜鶘的模型。
標籤
IBM Granite大型語言模型圖像生成模型評估GGUF量化模型
以上為 AI 自動翻譯導讀。原文版權歸 Simon Willison 所有。 建議透過上方「閱讀原文」前往原始網站,以取得最完整資訊與支持原作者。