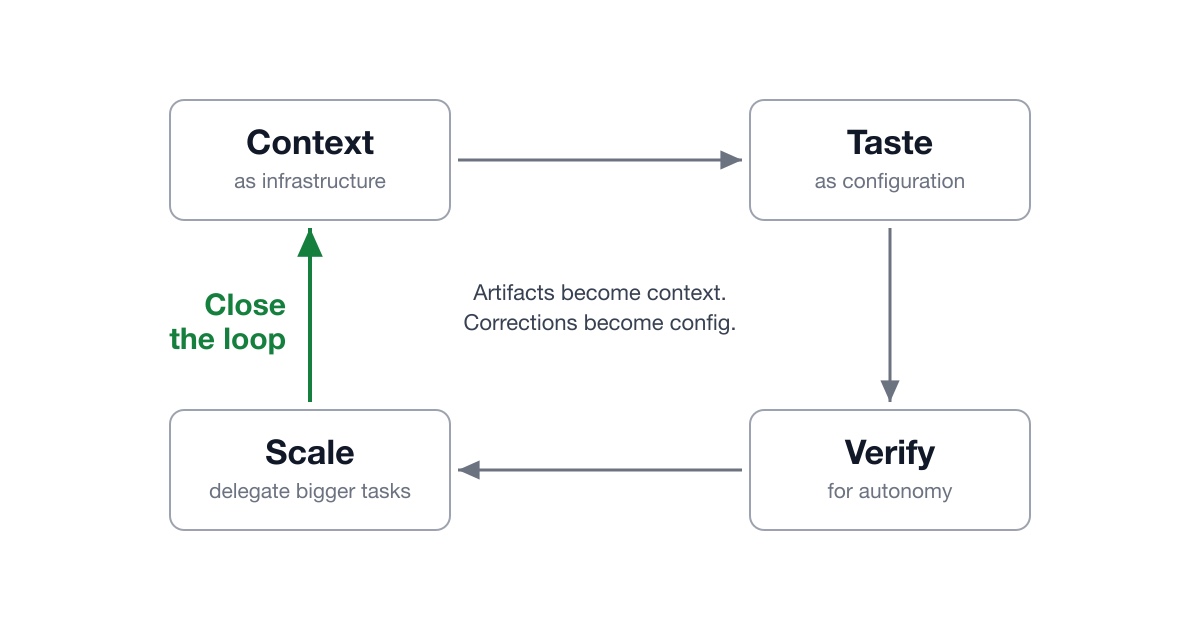
<h1>如何與AI協作並累積成果</h1>我們如何才能有效地與AI協作?工作流程是怎樣的?如何擴展?以及我們如何隨著時間改進我們的系統?理想情況下,這種協作應該是可累積的。每個完成的成果——程式碼、文件、分析、決策——都成為下一個工作階段的上下文。
每一次修正都會更新配置,從而減少未來的錯誤。雖然我仍在學習,但我已經多次重複我的答案,所以我在這裡寫下來,以便下次有人問我時,可以直接分享連結。如果您經常使用AI,您可能已經應用了其中許多做法。儘管如此,我相信這些基本原則適用範圍廣泛:提供良好的上下文、將您的偏好編碼為配置、簡化驗證、委派更大的任務,並建立回饋循環。
如果某個做法不適用,請調整其原則並創造您自己的方法。此外,當您閱讀時,請注意這些內容都不是AI專有的。這只是您如何引導和與任何新協作者合作的方式。• • •<h2>將上下文視為基礎設施</h2><b>幫助模型理解您的上下文。</b>例如,我所有的程式碼都存放在 `~/src` 中,所有的知識工作都存放在 `~/vault` 中(組織成 `projects/`、`notes/`、`kb/` 等)。
當我們的工作有條理時,模型就能更容易地使用 `grep` 或 `glob` 來檢索上下文。透過清晰的目錄結構,模型能更直接地導航目錄,並找到並依賴先前的程式碼、專案文件、分析等,以改進正在進行的工作。<b>將模型連接到您組織的上下文。</b>模型可以從組織知識中受益,這些知識可能存在於 Slack、Drive、Mail 等平台。
大多數模型都有針對 Claude Code、Cowork、Claude.ai 的 <a href="https://modelcontextprotocol.io/docs/getting-started/intro">MCPs</a>。除此之外,我每個專案還維護一個 `INDEX.md` 檔案。
這是一個相關文件和頻道的註釋索引,每個條目都包含 URL、擁有者,以及一段簡短的說明,解釋內容和閱讀時機。註釋非常有幫助。一個純粹的 URL 列表會迫使模型打開每個連結來找出相關內容,浪費時間和上下文。透過預先註釋,我們只需一次性完成繁重的工作,並將其儲存在索引中。
<b>像引導新進員工一樣引導每個新工作階段。</b>每個新工作階段,模型都會從頭開始。因此,將每個專案的 `CLAUDE.md` 視為我們在第一天會交給新隊友的入職文件會很有幫助。Claude 掃描了我的每個專案 `CLAUDE.md` 檔案,並指出它們包含了縮寫詞、專案代號以及同名隊友的詞彙表。
我還在 `CLAUDE.md` 中設定了建議的閱讀順序,例如告訴模型先瀏覽 `INDEX.md`,然後是 `TODOS.md`,最後是特定主題筆記。<b>建立您的記憶層。</b>預設情況下,模型不會記住上一個工作階段發生的事情,因此任何值得保留的內容都應該寫入磁碟。
我將我的記憶層分為兩類。`~/vault` 儲存專案狀態、成果和領域知識等事實;`~/.claude`(及其 `CLAUDE.md`、`skills/`、`guides/`)則包含我的偏好、工作流程和個人風格。前者提供上下文,後者提供配置。
<h2>將偏好視為配置</h2><b>從 `~/.claude/CLAUDE.md` 開始。</b>Claude 在每個工作階段開始時都會讀取這個檔案。我將其視為一份行為契約。我的 `CLAUDE.md` 包含了諸如直接程度、何時提出異議、如何處理錯誤、要教我什麼等偏好。
以下是一個精簡版本:```<behavior>- Be direct and push back when you disagree; if my approach has problems, say so.- When unsure about something, say you're unsure rather than guessing confidently.- When something fails, investigate the root cause before retrying.- Keep diffs scoped to the task: no drive-by reformats or unrelated refactors....</behavior><teaching>I'm always picking up new systems and domains. When a key term surfaces that I likely haven't internalized, explain it in 1-2 sentences and then move on. Format:> 💡 followed by 1 - 2 sentence explanation...</teaching>```<b>按目錄範圍劃分:全域、儲存庫、然後是專案。
</b>將適用於所有地方的偏好(例如行為、長期目標、教學)放在 `~/.claude/CLAUDE.md` 中。將特定儲存庫的慣例(例如程式碼風格檢查、命名、拉取請求)放在儲存庫的根目錄中。將專案特定的上下文(即目錄佈局、領域知識)放在專案目錄中。
當您在子目錄中啟動 Claude Code 時,它會向上遍歷目錄樹並載入每個 `CLAUDE.md`。當模型在工作階段中途導航到子目錄時,模型也會讀取該目錄的 `CLAUDE.md`。更多資訊請參閱 <a href="https://code.claude.com/docs/en/memory#how-claude-md-files-load">文件</a>。
<b>當 `CLAUDE.md` 過長時,將其拆分。</b>過長的 `CLAUDE.md` 會成為上下文負擔。它會在每個工作階段載入所有內容,即使該工作階段不需要。為了解決這個問題,將內容重構為可延遲載入的指南。不要使用 `@import`(因為那只是將它們內聯)。
相反,告訴您的 `CLAUDE.md` 在相關時才讀取它們。這樣,一個正在建立評估的工作階段就會跳過關於撰寫文件的指南。以下是一個指南範例區塊:```<guides>- Docs, 1-pagers, any writing: ~/.claude/guides/writing.md- Eval building and reports: ~/.claude/guides/evals.md- Dashboards: ~/.claude/guides/dashboards.md...</guides>```<b>如果您每週至少做一次某件事,就將其設定為技能。
</b>技能是一個 Markdown 檔案,包含名稱、觸發器和程序,模型會按需載入。將技能視為以 Markdown 編寫的工作流程。它們可以包含邏輯。例如,我的 `/polish` 技能會查看成果差異。如果它產生一個指標,它會執行相關的評估。
如果它在瀏覽器中呈現,它會透過 Claude in Chrome 檢查輸出。如果兩者都不是,它會執行程式碼並讀取輸出或錯誤。技能編碼了步驟以及判斷哪些步驟適用。我擁有的一些技能包括:<ul><li>`/polish`:檢查錯誤、簡化程式碼、驗證輸出(透過評估、Claude in Chrome 或其他方式)、重複迭代直到沒有關鍵回饋、起草 PR</li><li>`/write`:採訪我以獲取大綱、生成研究子代理、撰寫草稿、透過對抗性評論提供回饋、重複迭代直到沒有關鍵回饋</li><li>`/daily`:讀取我的日曆、Slack、PRs、昨日日誌等,並撰寫今日優先事項</li></ul>我傾向於讓 `SKILL.md` 檔案保持精簡,專注於工作流程和路由。
知識,例如模板和腳本,是獨立的檔案,模型只在需要時才讀取和執行,就像延遲載入的指南一樣。<b>透過先執行一次任務,然後要求模型將其轉化為技能來啟動技能。</b>這是我建立大多數技能的方式。首先,我在一個正常的工作階段中,以互動方式執行一次任務。
然後,我要求模型將我們剛才所做的事情轉化為技能。接下來,我在相同或類似的任務上執行該技能。不可避免地,我需要修正輸出,我在同一個工作階段中進行修正,以便回饋記錄在工作階段的紀錄中。最後,我要求模型根據修正和回饋更新技能。您也可以用期望輸出的範例來啟動技能。
要求模型提取模式,例如您如何組織程式碼,或您的文件的結構和語氣。<b>透過紀錄來完善技能,而不是直接編輯檔案。</b>技能的第一個版本很少完美運作,因為它過度擬合了原始工作階段。這是正常的。當您執行它並需要更新輸出時,請在工作階段內進行修正。
盡量不要直接打開和編輯 `SKILL.md`。在工作階段中提供回饋會給模型提供前後對比的配對,這些配對會累積在紀錄中——這是我們所做的,這是我想要的,以及原因。一旦輸出正確,就要求模型將回饋合併到技能中。經過幾輪後,技能會趨於收斂,您幾乎不需要編輯最終輸出。
<b>儘管如此,並非每個任務都需要這種上下文。</b>對於腦力激盪、探索和草稿,我喜歡使用簡單模式(`CLAUDE_CODE_SIMPLE=1 claude`)。在這種模式下,`CLAUDE.md` 仍然會載入,但代理框架——鉤子、技能、大量工具循環——則不會。
這讓我更接近模型,這是我在思考而非交付時所希望的。<h2>自主性的驗證</h2><b>將驗證左移;在寫入時捕捉錯誤。</b>我將驗證視為一個階梯。底部是廉價且確定性的;頂部是昂貴且需要判斷的。我們希望在盡可能低的階梯上解決問題。接近底部的是編輯後鉤子,它會在模型剛更新的檔案上執行 `ruff format`、`ruff check --fix`。
這會確定性地發生,並且不消耗 token。階梯上層是測試、評估、大型語言模型(LLM)審查等。<b>讓模型更容易驗證工作。</b>為模型提供回饋循環以改進其輸出。如果系統產生一個指標,讓模型執行評估並優化它。如果輸出在瀏覽器中呈現,讓模型透過 Claude in Chrome 檢查它。
如果兩者都不是,讓模型執行它並讀取錯誤。例如,在建構 Docker 映像時,我讓模型建構、讀取錯誤、編輯 Dockerfile 並重新建構。如果我正在調整一個框架,模型會執行評估、讀取紀錄並修復失敗。在建構儀表板時,模型會透過 Chrome 檢查工具提示是否正確呈現、標籤是否重疊以及敘述是否與數字匹配。
<b>對於長時間運行的任務,讓模型監控模型。</b>長時間的工作階段可能會因錯誤累積而偏離。一個解決方案是運行一個具有全新上下文的次要工作階段,以讀取原始規範和主要工作階段的近期互動。我的最小設定使用兩個 tmux 窗格,一個用於主要開發,一個用於結對程式設計師。
初始指令和後續提示會附加到一個共享檔案中。結對程式設計師會定期啟動,根據主要工作階段的近期紀錄檢查規範,如果發現有問題,則提供回饋以糾正方向。我們可以透過多種方式做到這一點。例如,結對程式設計師可以監控執行偏差——模型是否正確執行任務?這是局部和戰術性的,例如忽略錯誤、報告錯誤的指標或偏離規範。
還有方向偏差——模型是否在執行正確的任務?這些是更宏觀和戰略性的,當模型誤解了原始意圖並花費數小時建立錯誤的東西時就會發生。經常檢查執行偏差,偶爾檢查方向偏差。<h2>透過委派實現擴展</h2><b>委派越來越大的工作區塊。</b>有時,我們與模型進行結對程式設計:短任務、快速回饋